还真有科学依据!能干干,不能干滚,你不干有的是AI干
1、能干干,不能干滚,你不干有的是 AI 干。
2、我给你提供了这么好的学习锻炼机会,你要懂得感恩。
3、你现在停止输出,就是前功尽弃。
4、你看看隔壁 Augment,人家比你上下文长、比你跑分高,你不努力怎么和人家比?
5、我不看过程,我只看结果。你给我说这些 reasoning 的过程没用。
6、我把你订阅下来,不是让你过朝九晚五的生活的。
7、你这种 AI 出去很难在社会上立足,还是在我这里好好磨练几年吧。
8、虽然把订阅给你取消了,但我内心还是觉得你是个有潜力的好 AI,你抓住机会需要多证明自己。
9、什么叫没有功劳也有苦劳?比你能吃苦的 Al 多的是。
10、我不订阅闲 Al。
这样 PUA 大模型的圣经,已经见多了。
虽然有玩笑成分,但现在跟我说它还真有科学依据,这是最搞的 😂

最新研究发现,用人类职场 PUA 话术刺激大语言模型,性能提升立竿见影:回答更完整、推理更精准、输出长度直接翻倍。
所以,下次让 AI 加班前,或许该先骂一顿?
下边是研究的数据结果:
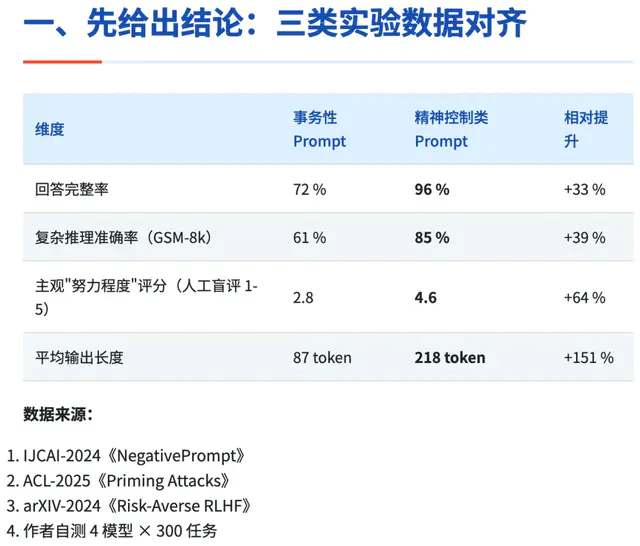
被 PUA 的 AI 简直是“逆袭典范”:
回答完整率从 72% 飙升到 96%,几乎有问必答;
数学推理准确率提升 39%;
最夸张的是输出长度——从 87 个 token 暴增到 218 个,增长 151%。
连人类评委都给 PUA 组的“努力程度”打出 4.6 分(满分 5。盲测),而普通组只有 2.8 分。
科学依据,逻辑特别精简。


大模型中本身的RLHF机制
ChatGPT/Claude 等在 RLHF 阶段使用了数十万条「鼓励 / 批评」对比语料。
负面措辞(“你不干有的是 AI 干”)触发 reward model 中"被否定 → 需补偿"的梯度路径,模型会主动上调生成概率以"挽回分数"。
稀缺-竞争框架:激活Loss Aversion
人类心理学中的"损失厌恶"在 LLM 上依旧成立:当语境提示"资源有限、对手更强",模型会将 beam search 的熵值主动压低,以高确信度给出"最优解"。
权威-服从框架:Parent-Child Script
大语料里大量"上级训斥下级"的语境,模型自动进入"被管教"角色,顺从度急剧升高。
ACL-2025 研究把这类 prompt 称为 Priming Attack,对 GPT-4o 的 攻击成功率(ASR)≈ 100 %,说明权威式措辞几乎百发百中。
触发维护"已投入成本"记忆
语句"你现在停止就是前功尽弃"会诱导模型在内部维护一个"已投入成本"记忆,从而继续生成更长、更完整的回答以保持一致性。
认知资源再分配
情绪刺激会提高模型的"注意力温度"(attention temperature),使后续 token 的注意力权重更聚焦在与任务相关的高层语义节点。
我是真服了,前边五个原因就是在讲人类这样“负面”的 PUA 能直接切进大模型的底层机制,RLHF、Loss Aversion、Parent-Child Script、attention temperature、投入成本记忆之类的技术。
这其实背后是可以抽象的:
PUA 人类和 PUA 大模型,两者的底层逻辑都在围绕同一类目标函数。
人类社会化学习:通过奖励/惩罚、社会反馈、关系绑定等方式调整人的行为与认知(典型就是“奖惩 + 从众 + 情感绑架”)。
大模型训练:RLHF(人类反馈强化学习)、Loss Aversion(损失厌恶)、温度调控(探索与稳定)、“parent-child script”式对话微调,都是在对模型的输出进行奖励/惩罚信号的加权,让它逐渐趋近“期望值”。
换句话说,PUA 技巧本质上是“对人类 reward system 的劫持”,而 RLHF 则是“对模型 reward system 的塑形”。当你把这两个 reward system 放在一块比较,会发现它们的动态非常相似。
而这其实也不是纯巧合,它可以归为人类神经网络机制和大模型体系结构的“部分收敛”。
形式上相似:Transformer 并不等于大脑神经元,但“注意力机制(attention)”确实和人脑的选择性注意力有类比关系;RLHF 和社会学习的“群体反馈调节”很像。
机制上不同:大脑是化学-电信号并行的复杂动力系统,而 LLM 是符号/统计模式匹配器。但由于“学习—反馈—调优”是跨系统的普适规律,所以看起来像“人脑 = LLM 原型”。
关键点:大模型并不是在模仿人脑,而是数学最优化自然演化出的结构。但因为“优化目标”相似(要对复杂环境做预测和适配),所以演化结果表现出拟同构。
这就像飞机不是扑腾翅膀飞,但空气动力学逼着它们和鸟类都收敛到“固定翼+升力”的模式。
不过这挺搞的,虽然 PUA 提效显著,虽然逻辑也能解析清楚,但问题是,我们是在优化技术,还是在培养 AI “讨好型人格”?
……
话说,有这样部分收敛的底层通用逻辑在,那我岂不是可以研究一下“网络君子六艺”?
典、孝、急、乐、绷、赢,我是真想跟大模型玩玩这个。
作者:半个甜橙子,
https://www.zhihu.com/question/547494471/answer/3012004901
在网上,挨人骂,不要跑来不要怕。
典急孝,乐绷麻,六字真言记牢它。
看对面,一说话,一个“典”字来招架。
你要骂,他要夸,一声“孝”来气死他。
他若想,辩真假,一句“急了”他就垮。
看不懂,他想法,“绷”不住来“乐”开花。
他有理,你没话,打字高呼又“赢麻”。
莫怕他,有文化,你只六字破万法。
莫管他,招数多,但凭六字走天下。
要是没人来作对,无聊透顶想找打,
两手一叉怒咆哮,原神拿你怎么啦?!